
Dle plánů firmy Intel, která je patrně nejvlivnějším členem konsorcia PCI-SIG, má být PCI Express nástupcem sběrnice PCI v roli univerzální systémové sběrnice pro připojování periferních zařízení. (Pozn.: označení se neoficiálně často zkracuje na PCI-E.)
Zatím jde o relativní novinku, která se objevila v poslední generaci čipsetů a základních desek. Většině odborné veřejnosti je patrně známa především jako "nástupce AGP" - což je ve skutečnosti jenom vrcholek ledovce všech schopností a plánovaného budoucího nasazení.
V tomto povídání se tedy podíváme na vlastnosti sběrnice PCI-E poněkud systematičtěji a důkladněji. Často budeme srovnávat s klasickou sběrnicí PCI.
PCI 32bit @ 33 MHz = 132 MBps - základní "modul"
PCI 32bit @ 66 MHz = 266 MBps
PCI 64bit @ 33 MHz = 266 MBps
PCI 64bit @ 66 MHz = 533 MBps
PCI-X 64bit @ 100 MHz = 800 MBps
PCI-X 64bit @ 133 MHz = 1066 MBps
Takt: typicky = 2.5 Gbps = 250 MBps
teoreticky = až 10 Gbps = 1 GBps
PCI-E x1 = 250 MBps
PCI-E x2 = 500 MBps
PCI-E x4 = 1 GBps
PCI-E x8 = 2 GBps
PCI-E x16 = 4 GBps
PCI-E x32 = 8 GBps
Takt = 2.5 Gbps.
PCI-E x1 = 250 MBps
PCI-E x4 = 1 GBps
PCI-E x8 = 2 GBps
PCI-E x16 = 4 GBps
Klasická sběrnice PCI je paralelní a polo-duplexní - všechny vodiče slouží pro přenos dat oběma směry, ovšem nikoli oběma směry zároveň.
Na rozdíl třeba od sběrnice ISA nemá PCI adresní část oddělenou od části datové - charakteristický počet vodičů (32 nebo 64) slouží pro přenos dat i adres, adresa se posílá na začátku každé transakce.
Sběrnice PCI-E je sériová, resp. sério-paralelní, a plně duplexní - základní modul sběrnice má jeden symetrický pár vodičů pro TX a druhý pro RX a sběrnice skutečně běží v plně duplexním režimu, pokud to charakter provozu umožňuje.
Základní modul ("x1") sběrnice PCI-Express má v podstatě jediný sériový fullduplexní kanál, vyšší násobky (x2..x32) vznikají paralelním spřažením několika těchto základních kanálů.
Tradiční paralelní sběrnice PCI se prakticky vyskytovala a vyskytuje v několika revizích (2.1, 2.2, 2.3), ve dvou šířkách (32 a 64 bitů) a s několika taktovacími frekvencemi. Existuje značná míra zpětné kompatibility v oblasti taktovacích frekvencí, dokonce i co do šířky sběrnice (64bitová karta jde zasunout do 32bitového slotu a naopak).
Pokud pomineme chyby v implementaci, problémy s kompatibilitou se vyskytují v zásadě pouze v oblasti rozdílů mezi revizemi, především v napájecích napětích (3.3 vs. 5 V) a někdy i v jiných okrajových vlastnostech. Vcelku jsou ale různá PCI zařízení navzájem velmi dobře kompatibilní.
V porovnání s tím je kompatibilita na PCI-E v některých ohledech omezenější, přinejmenším proto, že v žádném případě nelze zasunout širší kartu do užšího konektoru. Navzdory specifikaci lze očekávat také problémy s kompatibilitou hardwaru od různých ne-intelských výrobců v netypických kombinacích, např. pokud zasuneme nějakou "užší" kartu do širokého PCI-E konektoru určeného pro grafickou kartu. Možná i s ohledem na tyto aspekty se někteří autoři uchylují k prohlášením toho typu, že "PCI-E je svébytný praktický žert, který zašel příliš daleko".
Ale při použití hardwaru od "třetího výrobce" proti referenčním implementacím PCI-E od Intelu snad nebude tak zle, přestože errata k prvním generacím PCI-E čipsetů od Intelu jsou docela dlouhá.
Již u paralelní sběrnice PCI-X se projevovalo omezení počtu zařízení na jednom segmentu sběrnice, vynucené impedančními tolerancemi na vysokých taktovacích frekvencích. V souvislosti s dalším zvyšováním rychlosti tento směr vývoje pokračuje na sběrnici PCI-Express. Jednotlivé segmenty jsou přísně point-to-point a většího počtu připojených zařízení či slotů se dosahuje jedině bridgováním - resp. terminologicky přesně "switchováním".
Přes odlišnou topologii PCI vs. PCI-E a přes odlišnosti ve fungování nižších vrstev je nicméně PCI-Express od určité úrovně logické adresace a protokolů zpětně kompatibilní s klasickou PCI, tj. mj. také softwarově kompatibilní. Např. výpis utility "lspci" ze systému obsahujícího PCI Express je nápadný víceméně jenom počtem PCI bridgů, tj. košatostí stromu sběrnice PCI. Dalším projevem této kompatibility je fakt, že PCI provoz lze na sběrnici PCI-E bez problémů transparentně bridgovat.
Sběrnice PCI-E má teoreticky sice šest "šířkových" variant, reálně dotažené do fyzické podoby jsou však dosud pouze čtyři (viz tabulka rychlostí výše). Pouze pro tyto čtyři varianty existují standardizované konektory, a podle jejich rozložení vývodů se zdá, že např. s variantou x2 se nepočítá.
Teoretičtější (a více marketingově laděná) pojednání o sběrnici PCI-E hovoří a naznačují v tom smyslu, že jednotlivé základní stavebné "kanály" sběrnice PCI-E (zvané "lanes", tj. "jízdní pruhy") si žijí do značné míry vlastním občanským životem, díky inteligentním switchům je lze je libovolně "svazkovat" do širších násobných sběrnic, různé kanály v rámci jednoho svazku mohou být vyhrazeny pro různé třídy provozu či snad pro různé jednotlivé relace, na které postačuje jejich kapacita. Zdá se však, že tyto vzletné myšlenky nemají oporu v realitě.
Realita je následující:
Existuje výše uvedených šest teoreticky možných šířkových stupňů, ale pouze čtyři z nich jsou prakticky vydefinované až do podoby konektorů.
Konektory PCI-E pro různé "násobky" jsou různě dlouhé, nicméně mají společnou rozteč vývodů a "ideově jednotnou" modulární stavbu.
Konkrétně vždy začínají modulem společných vodičů, který je pro různé šířky PCI-E vždy stejně široký. Tento společný modul obsahuje napájecí vodiče 3.3 a 12 voltů, pomocné sériové sběrnice SMBus a JTAG, plus několik málo dalších řídících signálů. Za tímto společným modulem následuje přepážka. (A za ní jeden společný pár vývodů, který přenáší společné isochronní hodiny.)
Dále následuje jeden (x1) či více modulů, které odpovídají jednotlivým datovým kanálům (lanes). Sada vývodů pro konkrétní kanál (lane) je v zásadě pevná - modul vždy obsahuje páry RX a TX plus několik signálových zemí.
Celková šířka tohoto základního modulu (počet vývodů) v konektoru PCI-E není u různých kanálů úplně jednotná, protože některé moduly mají navíc jeden či dva speciální či rezervované vodiče. Pozice datových modulů (i jejich jednolivých vodičů) v PCI-E konektorech různé šířky si však navzájem odpovídají a čísla kanálů jsou "kompatibilní směrem dolů". Jednotlivé kanály jsou vzestupně číslovány od prvního, který sousedí se "společným modulem".
Konektor PCI-E má přepážku pouze mezi společným modulem a prvním datovým modulem. Datové moduly nejsou navzájem odděleny přepážkami.
Posledním datovým modulem konektor PCI-E končí, žádné další signály neobsahuje.
Každý kanál (lane) je na úrovni hran samostatně taktován, nezávisle na sousedních kanálech ve svazku. Díky tomu, že jednotlivé kanály neběží přesně synchronně ale pouze isochronně, návrhář motherboardu zřejmě při návrhu plošných spojů není nucen používat tolik "prodlužovacích serpentin", které jsou velmi dobře vidět na několika posledních generacích desek s rychlými a širokými paralelními sběrnicemi (FSB, RAM, PCI, AGP, U320 SCSI).
Na konci posledního datového modulu pro každou typizovanou "šířku" PCI-E (z výše uvedených čtyř) je umístěn speciální řídící signál pro detekci hot swapu. Tyto signály jsou přítomné i ve všech širších variantách konektoru. Konektor x16 tedy vedle svého vlastního uzavírajícího hotswap signálu obsahuje i hotswap signály odpovídající konci modulu x8, x4 a x1 (nikoli x2!).
Navíc při inicializaci sběrnice PCI-E se údajně každý kanál PCI-E ("lane") v rámci konkrétního násobného portu navazuje samostatně, takže při zasunutí karty před spuštěním počítače teoreticky nejsou hot-swap signály pro detekci šířky zasunuté karty zapotřebí.
Z výše popsané stavby konektorů vyplývá, že do širšího konektoru obecně lze zasunout užší kartu a výsledkem bude mechanicky, elektricky a logicky kompatibilní propojení vodičů. A pokud to bude podporovat konkrétní použitý čipset (což by měl), bude tato konfigurace platná a funkční. Prostě se navážou pouze dostupné kanály obsloužené zasunutou kartou a na nadřízeném switchi se automaticky nakonfiguruje sběrnice o dílčí šířce.
V této souvislosti se dokonce zdá, že někteří výrobci používají PCI-E x16 konektor na všechny druhy slotů (tj. včetně těch, které jsou elektricky "užší").
Existující konkrétní implementace PCI-E v PC čipsetech dávají navenek k dispozici porty pro výše uvedené čtyři fakticky podporované "násobky". Např. NorthBridge Intel 7520 má 3 porty PCI-E x8, i7525 má 1 port x16 a dva porty x4.
Dokumentace těchto konkrétních čipsetů říká, že konkrétní PCI-E porty lze "půlit" - tj. že designér motherboardu může např. na jeden x16 port elektricky "nadrátovat" dva x8 konektory a čipset mu díky alternativní konfiguraci umožní skutečně na tomto dvojném portu provozovat dva plnohodnotné segmenty PCI-E x8. Obdobně jeden x8 port může být při návrhu motherboardu rozdělen na dva segmenty x4.
Z výše uvedených technických podrobností vyplývá, že tato možnost "půlení" (resp. obecně dělení) portů PCI-E rozhodně není samozřejmá. Navenek mají dva x8 porty přinejmenším odlišnou sadu hotswapových signálů než jeden x16 port, a ostatně také interní logika PCI-E rozhraní a switche je na několika vrstvách jiná pro dva x8 porty než pro jeden x16 port.
Z výše uvedeného také vyplývá, že toto "rozdělení portu" nemůže u hotového motherboardu nakonfigurovat sám uživatel, ale že jde jednoznačně o rozhodnutí, které je třeba učinit při návrhu motherboardu.
Navrhnout motherboard jako univerzální patrně nebude možné, a to kvůli impedanční optimalizaci plošných spojů pro "užitečné" signály RX, TX a CLK - univerzální deska by musela mít na jednom segmentu PCI-E dva konektory, což není přípustné.
Na druhou stranu dokumentace těchto intelských čipsetů hovoří jednoznačně v tom smyslu, že kterýkoli PCI-E port ochotně ustaví příslušnou užší sběrnici, pokud je do konektoru na motherboardu zasunuta užší karta - tj. např. port o šířce x16 se bez problémů dohodne s kartami x8, x4 a x1.
Data na jednotlivém kanálu (lane) jsou kódována systémem "osm z deseti", takže jeden užitečný bajt je transformován na desetibitový znak. Dostupné materiály mluví o tom, že přidané dva bity "vyvažují poměr nul a jedniček" a slouží k in-band synchronizaci hodin pro každý kanál (lane) zvlášť. V každém případě jde z pohledu kapacitních počtů o jednoznačnou a deterministickou režii. Proto se základní reálně používaná bitová rychlost (2.5 Gbps) při přepočtu na bajty dělí zásadně nikoli osmi ale deseti.
Frame na PCI-E, tj. sekvence bajtů, je rozkládán po bajtech (nikoli po bitech!) mezi jednotlivé kanály, a na dalším switchi=bridgi je z jednotlivých bajtů opět rekombinován. Zdá se, že jednotlivé kanály (lanes) mají vlastní krátké buffery, které umožňují vyrovnávat mírné rozdíly v délce elektrického vedení na jednotlivých kanálech v sério-paralelním svazku.
Tradiční paralelní sběrnice PCI používá poměrně jednoduché atomické transakce s minimem režie a redundance, při kterých si vydatně pomáhá pomocnými řídícími signály.
Oproti tomu PCI-E každou transakci rozdělí do dvou rámců, tj. na požadavek a odpověď. Každý rámec je opatřen sekvenčním číslem a kontrolním součtem, které lze vnímat opět jako čistou režii. Tyto rámce jsou poté transportovány tam a zpět kaskádou switchů v systému. PCI-E se tedy na nižších vrstvách mnohem více než klasické sběrnici podobá switchované paketové síti.
Pokud má sběrnice provádět plný duplex proti host bridgi, lze si to představit v případě DMA - tj. v případě, že několik periferních zařízení v bus-master režimu přenáší data oběma směry. Prosté "polled IO" těžko poběží v plném duplexu, protože by host bridge musel podporovat multithreading a "TCQ", což by asi nešlo zařídit transparentně pod úrovní procesorových instrukcí.
Jiné případy, kdy by se mohl uplatnit plný duplex, jsou hůře představitelné. Několik "host bridgů" lze uvažovat a tato konfigurace je patrně obecně podporována, ale není běžná - zrovna tak přímé přenosy dat mezi periferními zařízeními navzájem jsou na úrovni sběrnice samozřejmě podporovány, ale běžně se nepoužívají (snad s výjimkou specializovaného síťového hardwaru a s výjimkou několika experimentů v oblasti síťových stacků v open-source operačních systémech).
Obecně stromová struktura sběrnice teoreticky není orientována vůči host-bridgi (ačkoli praxe může být jiná, přinejmenším inicializace sběrnice se děje směrem od host bridge k periferním segmentům). Sběrnice má vlastní jednotný adresní prostor, který si operační systém běžící na hostitelském procesoru "překládá" do svého virtualizovaného paměťového prostoru (čímž je teprve umožněn jednotný přístup softwaru do RAM i do případných paměťově mapovaných oken exportovaných periferiemi na PCI).
Jak PCI tak PCI-E jsou nezávislé na procesorové platformě. Např. sběrnice PCI se vyskytuje ve spojení s procesory x86, PowerPC, i960, ARM/Xscale aj.
Jako úvod do problematiky doporučujeme relevantní pasáže staršího přehledového dokumentu o vývoji platformy x86 PC.
Konektor sběrnice PCI-E úplně postrádá vodiče pro tradiční diskrétní signály přerušení, charakteristické pro platformu x86 PC.
Sběrnice PCI-E totiž definitivně a důsledně uplatňuje nový způsob doručování přerušení na platformě PC: doručování pomocí zpráv (tzv. message-signaled interrupts).
Message-signaled interrupty se objevily jako volitelná vlastnost již na klasické paralelní PCI počínaje verzí 2.2, ale protože paralelní PCI na platformě PC je VŽDY vybavena klasickými IRQ signály (v novějších čipsetech v kombinaci s IO APICy), tato vlastnost se u PCI prakticky nevyužívala.
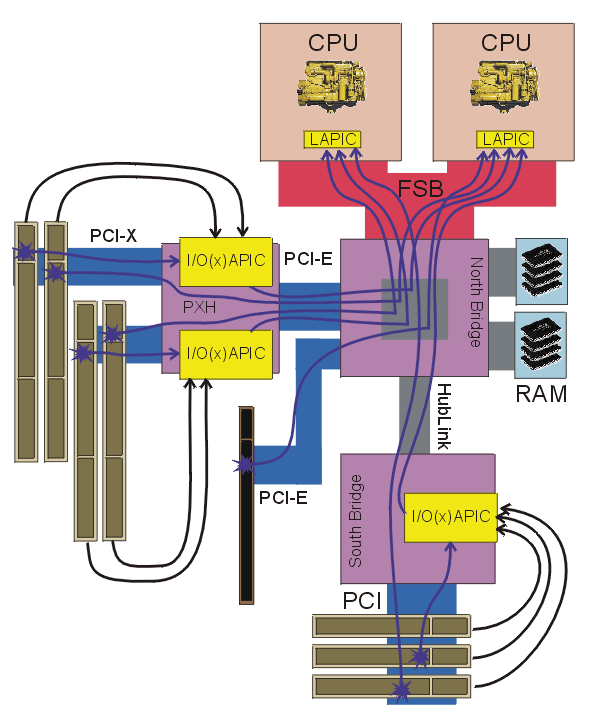
Resp. vlastně využívala. Součástí této pointy je odpověď na otázku, jak se v moderních Intelských čipsetech řady 8x a 9x doručují přerušení od IO APICu (součást S.B.) přes HubLink (emuluje PCI) a North Bridge na procesor, a také na otázku, proč mají tyto čipsety v porovnání s konkurencí tak dlouhou a nedeterministickou latenci obsluhy (pod zátěží PCI latence IRQ roste). IO APIC, který je součástí South Bridge, posílá přerušení směrem k procesoru v podobě zpráv na sběrnici HubLink (PCI). Než odešle tuto speciální zprávu, čeká na samovolné vyprázdnění odesílacích bufferů rozhraní HubLink. Proto je latence obsluhy IRQ větší, pokud z PCI teče do HubLinku nějaký provoz.
Ma tomto místě bude vhodné učinit terminologickou poznámku.
Klasický I/O APIC doručuje IRQ události směrem k procesoru prostřednictvím jednoúčelové sériové sběrnice zvané APIC Bus.
Novou variantu I/O APICu, která již pracuje s doručováním pomocí zpráv po sběrnici PCI, značí firma Intel velmi často zkratkou IO(x)APIC.
Pochopitelně v obou případech musí daný způsob doručování IRQ podporovat použitý procesor, resp. jeho on-chip subsystém zvaný "Local APIC".
Message-signaled interrupty jsou v každém případě softwarově zpětně kompatibilní, tj. transparentní vůči staršímu softwaru, který po jejich existenci nepátrá. Transparentní převod message-signaled interruptů na tradiční echanismus přerušení procesoru x86 probíhá za asistence host bridge (součást N.B.) a především modulu Local APIC, který je součástí procesorů x86 od Pentia výše.
Dlužno podotknout, že už v případě klasické PCI jsou elektrické signály jednotlivých IRQ sice součástí PCI konektoru, ale na úrovni logiky sběrnice, PCI bridgů apod. se jedná spíše o zcela nezávislý appendix, úlitbu architektuře x86 PC. IRQ na PCI je v zásadě samostatný drát, který vede od periferního zařízení k procesoru, resp. k jeho pobočníku zvanému I/O APIC. Slouží k tomu, aby periferní zařízení mohlo procesoru "poklepat na rameno", že se něco děje. Což nicméně nijak přímo nesouvisí s činností PCI sběrnice: po PCI sběrnici víceméně tečou datové rámce tam a zpátky. "Událost", resp. přerušení v tom smyslu v jakém je zná procesor, jsou zde poněkud cizím pojmem - pakliže tato událost není signalizována přenosem rámce.
PCI-E žádné "drátěné" IRQ signály neobsahuje. Proto pokud jejím prostřednictvím chceme k procesoru bridgovat provoz z koncového segmentu PCI-X, je třeba, aby IRQ signály tohoto segmentu obsloužil nějaký "out of band" řadič přerušení - v kontextu x86 PC patrně IO APIC.
IO APICy první generace se sériovou sběrnicí v samostatném pouzdře se však již prakticky nepoužívají, a IO(x)APIC integrovaný v South Bridgi je alokován IRQ signály od svého vlastního PCI portu. Elegantním řešením tedy je, integrovat potřebný IO/APIC do použitého PCI/PCI-E bridge. Konkrétně 6700PXH obsahuje dva IO(x)APICy, na každý port PCI-X jeden, které mají dohromady 16 diskrétních IRQ vstupů.
Pokud se začteme do příslušných pasáží katalogových listů různých south bridgů, north bridgů a PCI bridgů, dojdeme k možná překvapivému závěru, že "Message-signaled interupt" je vlastně dost široký pojem, do kterého spadá několik různých stupňů/způsobů/formátů doručování IRQ událostí:
Jak se vlastně může do celého systému doručování IRQ vložit software, který si je vědom message-signaled interruptů a rád by z nich nějak těžil?
Vlastně nic moc dělat nemůže. Aktivace IRQ se v softwaru tak jako tak projeví asynchronním voláním obslužné rutiny. Operační systém by měl nabízet jednotné interní API pro registraci obslužných rutin, a pokud má tu možost, měl by se snažit o minimalizaci sdílení IRQ signálů, protože sdílení IRQ snižuje výkon.
O konfiguraci dvou úrovní APICů a několika transformací původních událostí přerušení přes "čísla IRQ" až po vektory obslužných rutin se stará ACPI BIOS a na něj těsně naváže operační systém. Operační systém může nanejvýš upravit konfiguraci mapování v APICech k obrazu svému - v praxi se však spíše musí spoléhat, že ACPI tabulky v BIOSu popisující způsob "nadrátování" jednotlivých diskrétních IRQ signálů na APICy jsou v pořádku.
Různé obchodně laděné materiály o PCI Express od firmy Intel
http://www.intel.com/technology/pciexpress/devnet/docs/WhatisPCIExpress.pdf
http://www.intel.com/standards/case/case_pci.htm
http://www.intel.com/technology/pciexpress/devnet/
Přehled vlastností PCI Express - nezávislý autor
http://www.interfacebus.com/Design_Connector_PCI_Express.html
Katalogové listy klíčových součástek
i7525 north bridge
i7520 north bridge
i6700PXH PCI-X/PCI-Express bridge
i82801DB ICH4 south bridge
i6300ESB south bridge