K čemu je dobrý rádiem řízený zdroj času (přijímač), na tomto místě asi netřeba vysvětlovat. V některých nasazeních/aplikacích je z hlediska spolehlivosti a dostupnosti výhodné, pojistit zdroj času navrch ještě redundancí. Lze tu uplatnit klasický princip "no single point of failure", ovšem přistupují k němu další specificky "časovací" zádrhele a zřejmě také proprietární uspořádání hardwaru Meinberg.
Na první pohled se může zdát jako dobrý nápad, vybavit NTP server
dvěma rádiovými přijímači, aby NTPd mohl volit mezi dvěma zdroji
času - takže pokud jedno "rádio" ztratí signál nebo umře, druhý
přijímač funguje dál a NTP démon si vystačí s časovou informací
z jediného upstream zdroje.
Ostatně Meinbergové takové sestavy nabízejí, takže asi není o čem
dlouze debatovat, ne?
Bohužel problém je ve skutečnosti složitější...
Redundantní server je napohled zajímavé technické zařízení. Má dva rádiové přijímače ve dvou různých frekvenčních pásmech, navíc chytají signál od dvou různých poskytovatelů, kteří jsou financováni dvěma různými vládami... Čili toto jediné zařízení nabízí redundanci přijímačů, rádiových signálů včetně jejich zdrojů a sponzorských zemí.
Je třeba si ale uvědomit, že se stále jedná koncepčně o jediný box, v jediné lokalitě, který má jedinou procesorovou kartu = jedinou instanci NTP firmwaru, jediný napájecí zdroj (dá se koupit zdvojený, ale stojí to peníze navíc).
Přitom existuje jednoduché alternativní řešení, které má mnohé výhody: namísto jednoho složitého zdvojeného NTP serveru je možné pořídit dva jednodušší NTP servery, každý s jediným rádiem. Při vhodném rozmístění serverů může být výsledkem redundance včetně lokalit, napájecích zdrojů, CPU karet a instancí NTP démona.
Použití dvou upstream NTP serverů podporují i mnozí NTP klienti, kromě toho na obecných OS (Windows/UNIX) lze v roli klienta provozovat plnotučného NTP démona (např. referenčního open-source NTPd z www.ntp.org). Pro hloupé klienty, kteří umí použít nanejvýš jeden upstream NTP server, je možné na nějakém stávajícím serveru v LANce rozjet NTP službu (stratum 2), která bude čas ze dvou Meinbergů pro hloupé klienty agregovat/zálohovat. Nebo je možné, nakonfigurovat dva Meinbergy křížem proti sobě, aby soused posloužil jako NTP záloha pro případ, že lokální rádiový přijímač selže.
Pokud vyjdeme z nabídky produktů firmy Meinberg, mluví ve prospěch "varianty B)" ještě jedna skutečnost: zatímco redundantní server je k dispozici nejníže na platformě LanTime M300 a sama redundance zdrojů času má nehezkou cenovku, dva jednoduché servery lze pořídit na platformě LanTime M200 - a cenově vyjdou oba dohromady zhruba nastejno, jako jeden dvojitý M300/GPS/PZF.
Na druhou stranu je pravda, že M200 má jediný ethernet, zatímco M300
má ethernety dva. To může pro někoho představovat problém.
A M300 byť s jediným rádiem vychází citelně dráž než M200 (obchodní
politika firmy Meinberg).
Mimochodem - LanTime (s firmwarem v6) umí na všech Eth portech VLANový
trunk, s klikací konfigurací.
NTP podporuje redundanci více upstream serverů odpradávna
a z definice - redundance je součástí standardu. Hodnocení,
porovnání, filtrace a vážené zpracování více zdrojů času
je prováděno poměrně pokročilým algoritmem v několika krocích:
posuzuje se round-trip delay a jeho kolísání (jitter),
na bázi konsenzu kvóra se určí přibližný správný čas a z okruhu
kandidátů se algoritmem "vyloučení mimoňů" vyřadí "lháři"
(sedí v koutku pod hanlivou cedulí "falsetickers"),
mezi přeživšími se dále provádí jakýsi vážený průměr
a jeden nejlepší je zvolen za "vůdce" (sys_peer). Toto se děje
cyklicky / opakovaně jednou za nějakou dobu.
Jednoduché klientské aplikace pro NTP synchronizaci tenhle složitý
algoritmus neprovádějí, prostě se chytí prvního dostupného serveru
a hotovo, a nejlíp ani neštelují spojitě rychlost běhu, ale seřizují
hodiny skokem... Pokud chcete lepší vlastnosti, použijte v roli
klienta nějaký plnohodnotný NTP software (démona/službu).
Pokud si představíte NTP server s dvěma rádii, a máte trochu představu, jak se konfiguruje NTP (refclock drivery, PPS vstup a tak podobně), je Vám patrně jasné, že dvě rádia budou připojena dvěma sériovými linkami a nejspíš i dvěma PPS vstupy, však on si s tím NTPd už nějak poradí, obecným algoritmem podle jitteru.
No - ono to schéma možná vypadá u Meinbergů trochu jinak. Starší návod k M300/GPS/PZF by přitakával výše uvedené představě. Ovšem moderní IMS sestavy s dvěma přijímači fungují jinak. Obsahují povinně kartu zvanou IMS-RSC, která hlídá oba zdroje a slučuje jejich výstupy = přepíná na sloučený výstup sadu výstupních signálů buď z jednoho nebo z druhého přijímače. To znamená, že instance NTPd na CPU kartě nevidí dva přijímače, ale jenom jediný! A externí RSC karta (má své vlastní MCU) víceméně hlídá stavové příznaky na výstupu přijímačů, a když zaznamená na aktivním přijímači ztrátu signálu, přepne na zdravou zálohu.
Novější revize hardwaru LanTime M100, M300 atd. prošly jistým interním upgradem, nové vnitřnosti jsou zřejmě příbuzné plně modulárním šasi řady IMS. Takže čert ví, jak je to vlastně s tou redundancí u nově dodaných kusů LanTime M300/PZF/GPS. Zatím se zdá, že u M300 funguje redundance dvou rádií "po staru".
Ono to přepínání mezi dvěma přijímači pomocí hardwarové fail-over karty dává velmi dobrý smysl pro výstup signálů, které na rozdíl od NTP nepodporují redundanci nativně. Jedná se klasicky o sekundový pulz, výstup 10 MHz z lokálního oscilátoru přijímače apod.
Další věc je, že dva PPS vstupy zavedené do jediné instance
NTPd (a linuxového kernelu), to zní v principu docela zvláštně.
Oba mají jitter (viděno NTPd) v jednotkách mikrosekund,
reálně ještě mnohem nižší. NTPd mezi nimi patrně bude nějak vážit,
ačkoli na úrovni mikrosekund toho už mnoho "neureguluje" :-)
Kosmetickým vedlejším efektem bude "clock-hopping":
NTPd bude často měnit zvoleného "sys-peera" podle své
okamžité nálady. To je normální a neškodný jev v situaci,
kdy má NTPd dvě nebo víc shodně kvalitních referencí.
(Totéž budou dělat klienti nebo stratum 2 servery, zavěšené
na dva rádiové Meinbergy.)
Vůbec nesmyslně vypadá představa, že by se dvěma PPS vstupy
skrz PPS API přímo štelovala systémová časová základna
LanTime firmwaru = Linuxu. I pokud PPS API podporuje
více paralelních PPS vstupů, tak koncepčně jenom jeden
z obou PPS signálů může mít pravdu.
NTP serverů LanTime od firmy Meinberg se týká ještě jedna
další zvláštnost: ony mají dokonce dva režimy fungování.
Kromě režimu "vzájemná redundance", který byl podrobně popsán
výše, umí dvojitý LanTime ještě druhý režim fungování,
zvaný SHS (Secure Hybrid System): porovnává oba lokální
rádiové zdroje času, a pokud se navzájem odchýlí o víc
než nastavený rozdíl (factory default je pár milisekund)
tak vypne NTP službu. Jedná se o paranoidní ochranu
proti podvržení časového vstupu.
Pokud jedno či druhé rádio ztratí signál, může jet klidně
dál na volnoběh. Volnoběh ovšem znamená, že se časem bude
na lokálním oscilátoru kumulovat chyba v běhu času - a dříve
či později dojde k tomu, že LanTime v režimu SHS zjistí
rozdíl vyšší než je nastavená mez, a vypne NTP službu.
Popravdě tento režim býval jediným režimem fungování
u starších modelů s označením SHS někde v objednacím kódu.
Rádiem řízené NTP servery lze jednak provozovat samostatně (kdy server nemá nakonfigurovaný žádný záložní NTP zdroj), nebo je lze např. ve skupině propojit mezi sebou odkazy v konfiguraci, aby "si byli navzájem oporou".
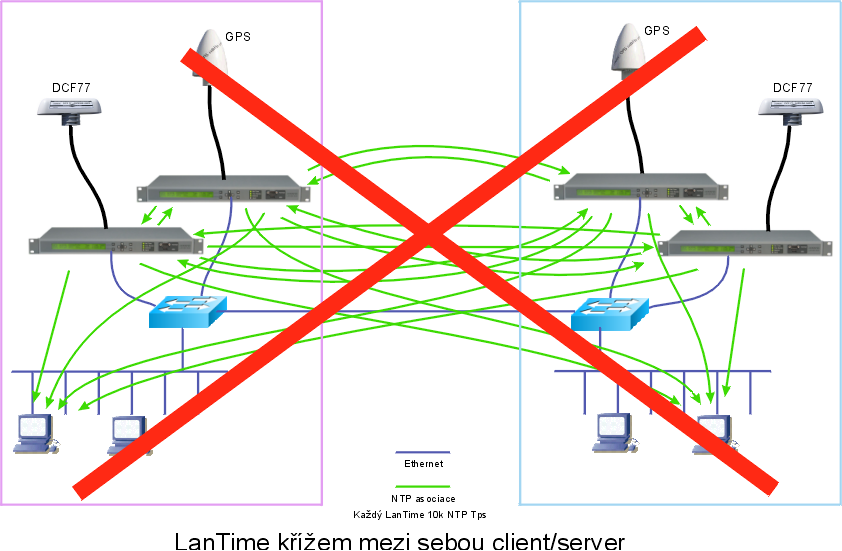
Člověka na první pohled napadne, použít prostý klient/server režim (v rámci asociace je jasně dáno, kdo je zdroj času a kdo je příjemce) - a tyto asociace prokřížit :-)
Ony už si to servery mezi sebou vyřídí, na základě
jitterů, strata a "RefID", jak se mají za sebou poskládat
do kaskády... je to tak?
Omyl, toto nefunguje. NTPd se této konfiguraci
brání. Pokud se o ni pokusíte, vynadá Vám do logu
že našel smyčku v konfiguraci (patrně na základě refid),
sousední servery nebudou vidět v ntpq -p apod.
Správná možnost je, nakonfigurovat "rovnocenným sousedům"
vzájemné vazby jako "peer to peer" asociace - tento
režim fungování je opět zakotven v NTP standardu.
Servery se i v tomto případě mezi sebou dohodnou,
kdo má přesnější čas a jak se mají na sebe navzájem
zavěsit.
Pokud je v serveru k dispozici lokální rádiový přijímač, měl by volbu "system peera" vyhrát proti NTP sousedům i čistě na základě změřeného jitteru. Přesto mají Meinbergové ve standardní konfiguraci lokální hodiny označené jako "preferred peera", tzn. lokální hodiny vyhrají vždy (pokud o sobě tvrdí, že mají signál).
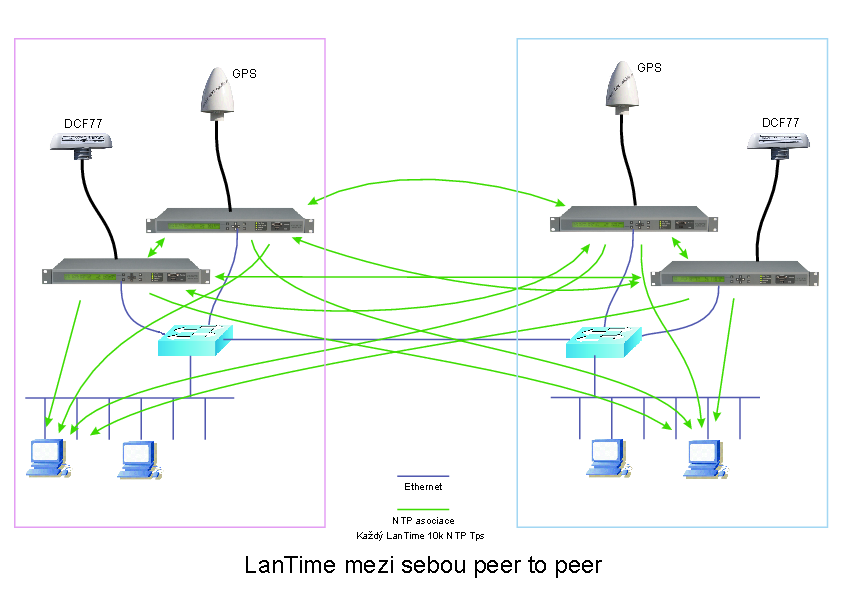
(Pozn. autora: delší dobu mám pochybnosti, na základě některých praktických zkušeností, jak se peer-to-peer režim chová doopravdy. Detekce smyček podle RefID totiž v principu funguje bezchybně pouze mezi dvěma peery. Pokud to není ošetřeno jinak, pak ve větší skupině peerů s dobrou vzájemnou viditelností můžou peerové navzájem "vyhrát volby" a začít se rozpustile vazbit/cyklit. Bohužel zatím nebyl čas to důkladně otestovat. Nicméně jedno jasné řešení se nabízí: striktní hierarchie.)
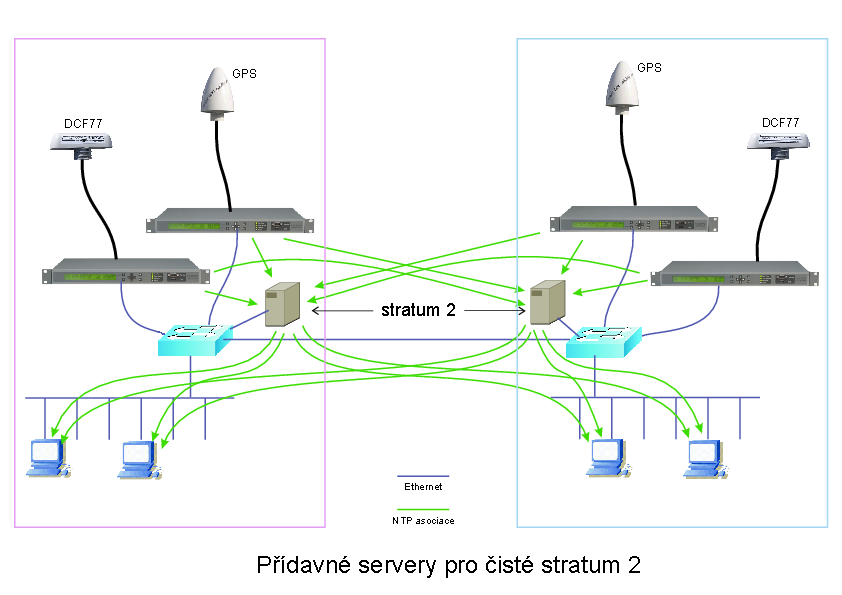
Pokud tedy cítíte averzi k porušování hierarchie ve stylu "já pán ty pán", je samozřejmě možné postavit topologii kaskády tak, aby se vznikům smyček zcela zabránilo už samotnou koncepcí. Pak je ovšem třeba, aby buď jednotliví klienti oslovovali více NTP serverů, nebo vložit do hierarchie další "patro" (stratum) = další server (nebo několik serverů).
Možná je samozřejmě také smíšená varianta, kdy slušně vychovaní NTP klienti (vycházející z referenční implementace NTP) se smí dotazovat přímo serverů na stratu 1, a problémoví klienti jsou odděleni vyhrazeným serverem ve druhém stratu.
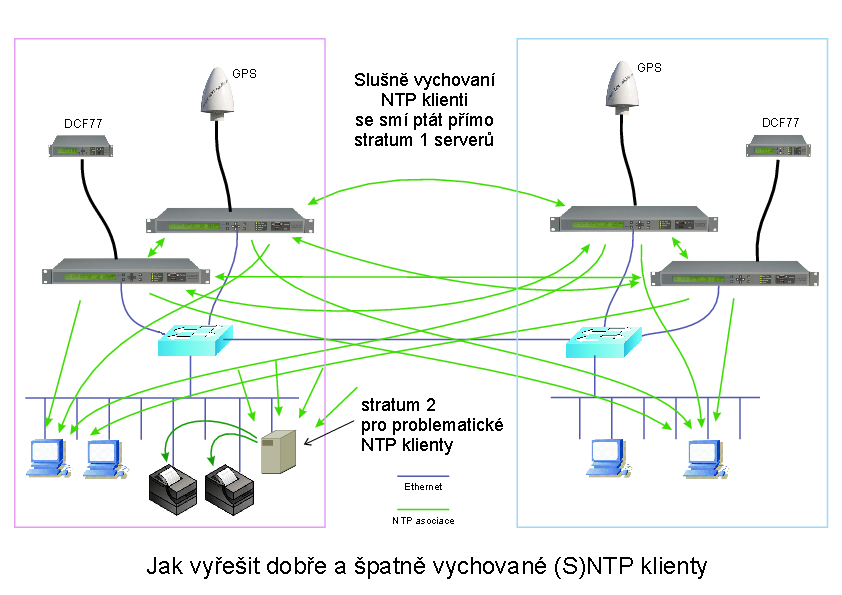
Potenciálně problémové jsou především jednoduché implementace SNTP klienta s častým dotazováním a sklonem k davovým psychózám. Meinbergové vypráví "historku z natáčení" o přepážkových tiskárnách před lety někde v nadnárodní bance: když NTP server vynechal odpověď, začal se klient ptát řádově častěji...
Servery Meinberg dále umožňují jednoduchý proprietární cluster.
Chová se to ideově podobně jako VRRP/HSRP, ovšem předává se
pouze IP adresa (patrně nikoli MAC adresa).
Každý NTP server má samozřejmě svoji vlastní
IP adresu, ale kromě toho si v clusteru předávají ještě jednu
další IP adresu, která je "putovní" - a na tu se zavěsí
hloupí klienti, kteří sami neumí používat dva nebo více
upstream serverů. Dá se také nakonfigurovat priorita
jednotlivých serverů v clusteru - např. pokud chcete,
aby v clusteru aktivně sloužil přednostně server s GPS
přijímačem, protože je o pár mikrosekund přesnější
a taky teoreticky trochu spolehlivější co do výpadkovosti rádia.
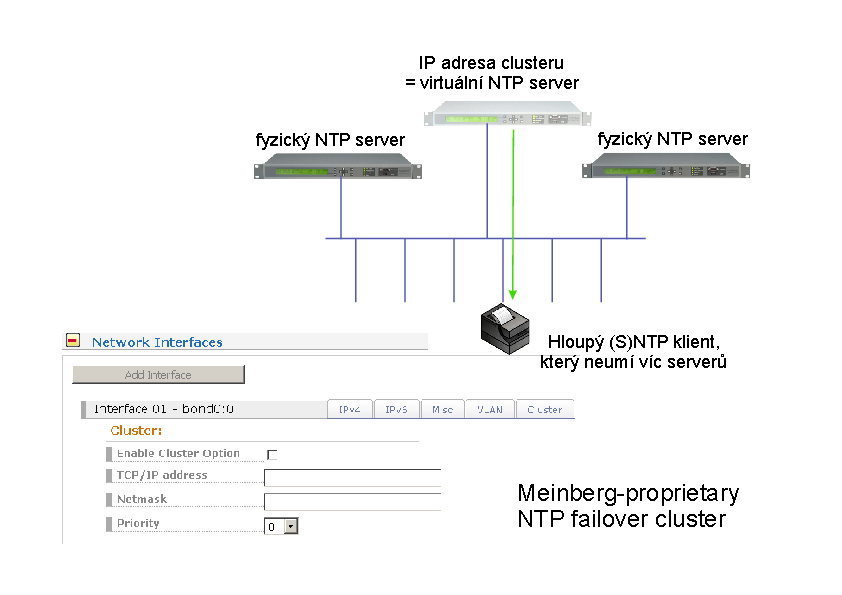
Cluster je službou pro hloupé NTP klienty.
Nijak neomezuje běžný provoz zúčastněných NTP serverů
na jejich vlastních IP adresách, ve smyslu zpracování
více upstream zdrojů, vzájemných záloh (ať už client/server
nebo peer-to-peer) apod.
Jinak řečeno, cluster řekněme 2 NTP serverů v rámci jedné
lokality lze zasadit do rozsáhlejší NTP hierarchie,
která se rozpíná napříč více lokalitami.
Redundance je hezká věc, ale je třeba si uvědomit ještě jeden háček: že dva upstream zdroje času sice stačí na prostý failover, ale neřeší situaci, kdy se obě rádia tváří spokojeně, a přitom se navzájem zásadně rozcházejí. To znamená, že má jedno rádio poměrně vzácnou poruchu, nebo mu někdo zmanipuloval vstupní signál. (Za normálních okolností rádiový přijímač času při sebemenším problému hlásí chybu, a tím se vyřadí ze hry.)
Na to, aby instance NTPd dokázala odhalit "falešného hráče" čistě podle dat, která od něj dostává, potřebuje alespoň tři upstream zdroje času. Pokud se jeden odchýlí, konsenzus kvóra vyhrají zbylé dva zdroje a lhář je vykázán z kola ven. Terminologicky přesně se takovému NTP lháři říká "falseticker".
Dlouhá léta Meinbergové uměli nabídnout pouze dva rádiové zdroje času: GPS a DCF77. Problém s podvržením rádiového signálu byli schopni "řešit" algoritmem SHS (viz výše v textu). Případně se jako třetí zdroj času pro srovnání dal použít nějaký (semi-)autonomní přesný zdroj: klasicky césium / rubidium / vodíkový maser, nebo alespoň speciální varianta LanTime zvaná MRS, která má přijímač upravený pro dlouhodobý volnoběh a osazený vysoce přesným krystalovým oscilátorem (Meinberg OCXO-HQ).
V dnešní době je možno použít jako třetí nezávislý rádiový zdroj přijímač ruského signálu GLONASS. Je od Meinbergů zdaleka nejdražší a oproti GPS o něco méně přesný.
Jako další varianta, dosud pouze částečně funkční, se nabízí
evropský systém Galileo.
Galileo má ve svých začátcích problém, že pro příjem přesného
času je třeba nejprve určit triangulací přesnou polohu přijímače,
což dnešních (březen 2017) asi 15 satelitů Galilea
na oběžných drahách zatím neumožňuje trvale.
Plánovaná plná funkčnost počítá s 30 satelity.
(Následně při stacionárním použití stačí vidět
trvale alespoň jednu družici, což už docela funguje.)
Firma Meinberg už pro Galileo dodává přijímač "GNS",
jedná se o nástupce původního Glonass-only "GLN"
za shodnou (nemalou) cenu. GLN i GNS jsou přijímače
multisystémové: GNS umí přijímat až tři systémy zároveň
(z množiny GPS, GLONASS, Galileo, Beidou),
ovšem v dokumentaci se nepíše, jak se přijímač zachová,
pokud se jeden ze systémů při paralelním příjmu "zblázní".
Proto v topologiích redundantních na úrovni NTP doporučujeme
konfigurovat GNS pro příjem pouze jednoho systému
- ať má NTPd šanci odhalit si falsetickera "po svém".
Jako třetí přesný zdroj času lze také použít autonomní přesný oscilátor, který se na globální čas dolaďuje pouze jednou za čas, pod lidským dohledem, nebo pomocí důvěryhodného privátního spoje na nějaký nadřízený spolehlivý zdroj času. Prostě autonomní hodiny s pouze občasným a hlídaným závěsem na nějaký upstream.
Pokud je v dané aplikaci užitečné, aby měl NTP server Meinberg dlouhodobě co nejlepší přesnost při volnoběhu (holdover), dá se pracovat s různými variantami lokálního oscilátoru. Výsledek je kompromisem mezi potřebnou přesností, dobou překlenutelného výpadku a cenou zařízení (oscilátoru).
Má-li zákazník/organizace vysoké požadavky (a rozpočet), může zvažovat různé topologie NTP s vícenásobným jištěním. Od zvolených počtů a druhů přijímačů (a NTP serverů) se bude odvíjet chování topologie v kritických situacích.
Topologie použitá v náčrtcích výše, tzn. dvě lokality
s dvěma jednoduchými NTP servery a dvěma rádiovými zdroji času,
vykazuje slušnou odolnost proti výpadku jednotlivého serveru
a proti výpadku konektivity mezi lokalitami.
Není ale odolná proti systematické manipulaci signálu
na vysílači (provozovatelem zdroje času) nebo proti
systematickému podvrhu ve větším měřítku (teoreticky
připadá v úvahu u DCF a jiných dlouhovlnných zdrojů).
Topologie (3 lokality) x (1 rádio) s třemi různými rádii dává na druhém stratu odolnost proti manipulaci jednoho zdroje, za předpokladu udržení konektivity mezi lokalitami.
Topologie (3 lokality) x (2 rádia) je koncepčně problematická. V případě rozpadu konektivity mezi lokalitami nelze zajistit odhalení falsetickera v rámci jedné odříznuté lokality, přestože dohlédnete v součtu za celou topologii na shodné zastoupení 3 různých rádiových zdrojů času, a je jedno, zda necháte dvě rádia na lokalitě pod palcem NTPd (outlier rejection, konsenzus kvóra) nebo budou dvě rádia na lokalitě podřízena striktním prioritám v IMS/MRS a teprve mezi lokalitami bude fungovat NTP mechanismus.
Odolnost proti současnému výpadku konektivity mezi lokalitami v kombinaci s manipulací jednoho rádiového signálu má varianta "3 x 3". V rámci sortimentu firmy Meinberg (nejdou osadit 3 rádia do jednoho šasi) tato varianta znamená, použít malé NTP servery, každý s jedním rádiem. A navázat na ně buď stratum 2 zavěšené na 9 "rádiových" serverů, nebo stratum 2 + 3 :-) Díky interní inteligenci NTP by "široké" stratum 2 mělo stačit.
Máte-li v lokální síti pohromadě dva a více přesných, rádiem řízených NTP serverů, velmi snadno se Vám stane, že budou hlásit vzájemný delay v desítkách mikrosekund a vzájemný jitter nad NTP na úrovni nízkých jednotek mikrosekund.
V takové situaci dochází k tomu, že další servery a klienti ve stratu 2, stejně tak "sousedé" ve vzájemně se zálohující skupině, se "nemohou rozhodnout", který z dostupných zdrojů je nejlepší. Žádný nevypadne na "outlier rejection", všechny s rezervou několika řádů splňují kritéria na kvalitu zdroje času, navíc všechny vykazují prakticky shodnou a téměř dokonalou přesnost. Ostatně - jitter v jednotkách mikrosekund, hlášený NTP serverem pro lokální rádiový přijímač, je zcela jistě na straně NTP serveru (PC hardware, obsluha IRQ a vyšší softwarové vrstvy). PPS výstup přijímače má jitter ještě o pár řádů níž. Jinak řečeno, jitter pozorovaný NTP serverem na lokálních hodinách je roven "šumovému pozadí" samotného NTP serveru.
Tato dokonalá přesnost několika zdrojů času ve vzájemné
těsné blízkosti má za následek, že jejich NTP klienti
"těkají" z jednoho zdroje na druhý. Děje se to při
"záměrně nepravidelných" iteracích NTP algoritmu
= jednou za pár desítek vteřin až v řádu desítek minut.
Problém je to čistě kosmetický - na klientském konci NTP asociace
nedochází k žádným skokům v čase, klient si prostě jenom náhodně
vybere podle poslední naměřené množiny jitterů pokaždé
jiný zdroj z "lokální skupiny".
Je případně trochu na pováženou, pokud se toto děje v chumlu rovnocenných blízkých serverů např. stratum 1 či 2, které jsou nakonfigurovány pro vzájemnou zálohu. Teoreticky by nemělo docházet k zacyklení více serverů, v peer-to-peer režimu (symmetric active/passive) k tomuto slouží stratum. Odhadem je třeba být opatrný u konfigurací "client/server do kříže".
Pokud chcete mít jistotu, vyhněte se "sousedským" NTP asociacím
a postavte topologii NTP serverů jako striktní hierarchii
- přestože to může znamenat, přidat trvalé stratum 2.
Při bližším pohledu je zřejmé, že i pokud nakonfigurujete
shluk serverů na stratu 1 pro vzájemnou NTP zálohu,
v okamžiku výpadku některého rádia se dotyčný NTP server
opře o nějakého souseda na stratu 1 a sám si sníží
stratum na 2. Čili "nejhorší případ" je v obou variantách stejný.
Zejména na dobře dimenzované LANce je jitter hlášený blízkými servery LanTime nad NTP asociacemi třeba jenom o řád horší, než jitter hlášený pro lokální rádiové zdroje - tzn. třeba v nízkých desítkách mikrosekund. Běžný server nebo desktop v roli čistého klienta je na zdravé LANce schopen se zasynchronizovat s přesností třeba 20-50 us, pokud má k tomu optimální operační systém (Linux). Pod Windows je přesnost času tradičně o poznání horší.
Stratum je mechanicky-administrativní údaj, který říká, na kolikátém patře NTP hierarchie se daný NTP server nachází = kolikátý v pořadí je od referenčních hodin se stratem 0 (stand-alone césium, vodíkový maser nebo nějaké rádio). Stratum je jenom pořadové číslo, které neznamená konkrétní přesnost.
NTP server (referenční implementace) se při volbě z několika upstream zdrojů zabývá především naměřeným jitterem, vcelku ignoruje absolutní round-trip delay (pokud je stabilní, umí ho odečíst). Důležité je, že mezi několika zdroji porovnává aktuální čas, a snaží se vyloučit menšinové "lháře" (falsetickers). Jestli ho něco opravdu nezajímá, tak je to stratum - prostě si přičte jedničku k upstream zdroji, který si momentálně vybral jako nejlepší (sys_peer => RefID).
Není třeba na údaji "stratum" kdovíjak lpět. S faktickou přesností NTP serveru souvisí jenom velmi volně. Faktická přesnost velice záleží na kvalitě konektivity a upstream NTP serverů, stratum je druhotné. Pokud setřídíte nějak vybranou skupinu NTP serverů z globálního internetu podle strata a podle faktické přesnosti, zjistíte, že ta dvě pořadí si navzájem neodpovídají.
Když je řeč o redundančních mechanismech a zapojeních, nebude od věci na okraj zmínit ještě jednu schopnost serverů Meinberg LanTime: channel bonding, jinde zvaný též Teaming (ovladače Intel) nebo Link Aggregation (IEEE 802 normy).
Základem LanTime firmwaru je Linux. Proto mechanismus vzájemné
zálohy více ethernetových portů, co do konektivity serveru vůči
okolní ethernetové síti, bývá v kontextu serverů Meinberg LanTime
nazýván linuxovým termínem "bonding". On se tak v Linuxu jmenuje
konkrétní
kernelový driver,
který umí spřáhnout více fyzických
ethernetových portů do jednoho virtuálního portu, za účelem
redundance nebo za účelem agregace přenosové kapacity. Celé se to
děje v druhé síťové vrstvě.
Lidský popis linuxového bondingu je k nalezení třeba na CentOS Wiki.
Více z nadhledu, v kontextu normy 802.3ad, probírá problematiku heslo "Link Aggregation" na Wikipedii.
LanTime OS v6 (uvnitř Linux) dává v konfiguračním rozhraní na výběr
2 varianty:
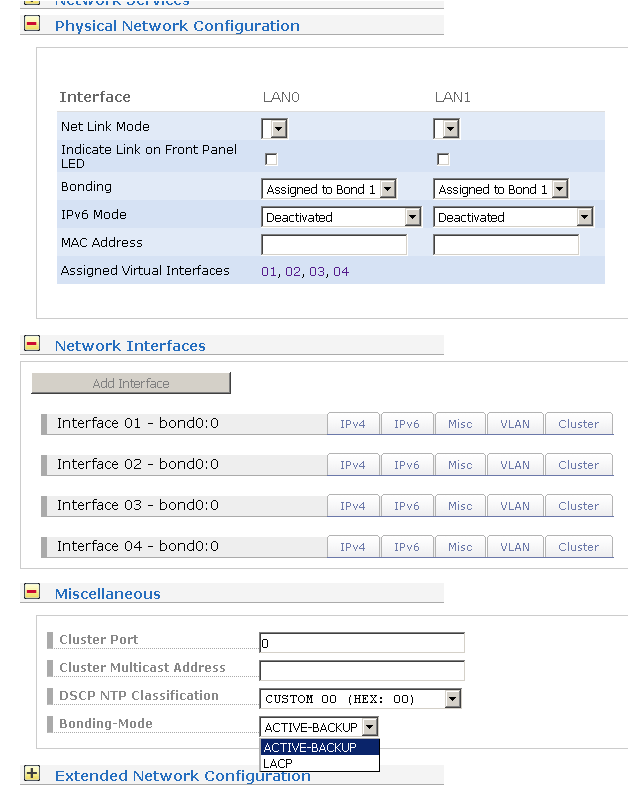
Je třeba si uvědomit, že protokol 802.3ad LACP dokáže jediný virtuální spoj (svazek několika fyzických spojů) navázat proti jedinému sousednímu switchi. V rámci serveru LanTime jedno virtuální rozhraní (bond<číslo>) znamená vždycky právě jeden sousední switch. Nelze navázat jeden LACP bond na dva různé switche. Lze navázat dva různé bondy - ale ty pak nefungují ve smyslu vzájemné zálohy. V zásadě tedy platí, že LACP neumí fungovat ve smyslu vzájemné zálohy portů/linků např. v populární dual-star topologii, která je běžným způsobem, jak zajistit "no single point of failure".
Naopak funkci "active/backup" umí linuxový "mode 1". Tento není nijak závislý na charakteru a schopnostech použitých switchů v síti (managed/unmanaged, s podporou STP nebo bez apod.). Linuxový "bonding" driver si hlídá lokální "link state" fyzických portů (patrně nástrojem miimon) a komunikuje vždy pouze na jednom z obou (všech) portů, aby nemátl switchům hlavu / nepřetěžoval síť re-learningem. Pouze pokud aktivní link umře a bonding driver přepne na zálohu, těsně po přepnutí vyšle pár ARP dotazů (gratuitous ARP), aby se síť naučila nový směr, kudy posílat data pro MAC adresu lokálního bondu.
LanTime OS nepodporuje vytváření softwarových bridgů (což je jinak běžná a bohulibá schopnost vanilkového linuxu). Tzn. nelze pro zálohu mezi více porty využít Spanning Tree Protocol.
LanTime (Linux) také neumí 802.1aq (SPB = STP + LACP na steroidech).
Dále je ještě možné uvažovat o redundanci na bázi NTP. Pokud máte NTP klienty, kteří umí použít dva upstream NTP servery (např. ntpd v roli čistého klienta), lze redundanci mezi více porty Lantime zařídit i tímto způsobem. Bohužel není možné, nakonfigurovat na dvou IP rozhraních serveru dvě různé IP adresy z téhož subnetu - Linux se v tom případě chová tak, že odchozí provoz posílá vždy pouze jedním rozhraním, bez ohledu na "link state". V tomto režimu lze proto zálohu nakonfigurovat jedině tak, že na LANce nakonfigurujete dva IP subnety - na sdíleném broadcastovém segmentu, tzn. nikoli v oddělených VLANách.
Sepsal: F.Ryšánek (poslední aktualizace 23.5.2017)